





Have you ever wondered how your favorite apps predict what you want next or how online stores recommend products just for you? The secret lies in machine learning data models.
These models are the engines powering smart decisions behind the scenes, and understanding them can unlock new possibilities for your projects or career. You’ll discover what machine learning data models are, why they matter, and how they can transform the way you work with data.
Ready to dive in and see how these models can give you an edge? Let’s get started!
Types Of Machine Learning Models
Machine learning models are tools that help computers learn from data. They find patterns and make decisions without being programmed for every task. Different types of models suit different problems. Understanding these types helps pick the right model for any task.
Supervised Learning Models
Supervised learning models learn from labeled data. This means the data has input and correct output. The model studies this data to predict outcomes for new inputs. Common examples include classification and regression tasks. These models work well when you have clear examples to learn from.
Unsupervised Learning Models
Unsupervised learning models work with data that has no labels. They find hidden patterns or groupings in the data. Clustering and association are common tasks here. These models help explore data and find structure without guidance. Useful for discovering unknown relationships in data.
Reinforcement Learning Models
Reinforcement learning models learn by trial and error. They receive feedback as rewards or penalties. The goal is to make decisions that maximize rewards over time. These models are common in robotics and game playing. They improve by interacting with their environment continuously.
Credit: www.geeksforgeeks.org
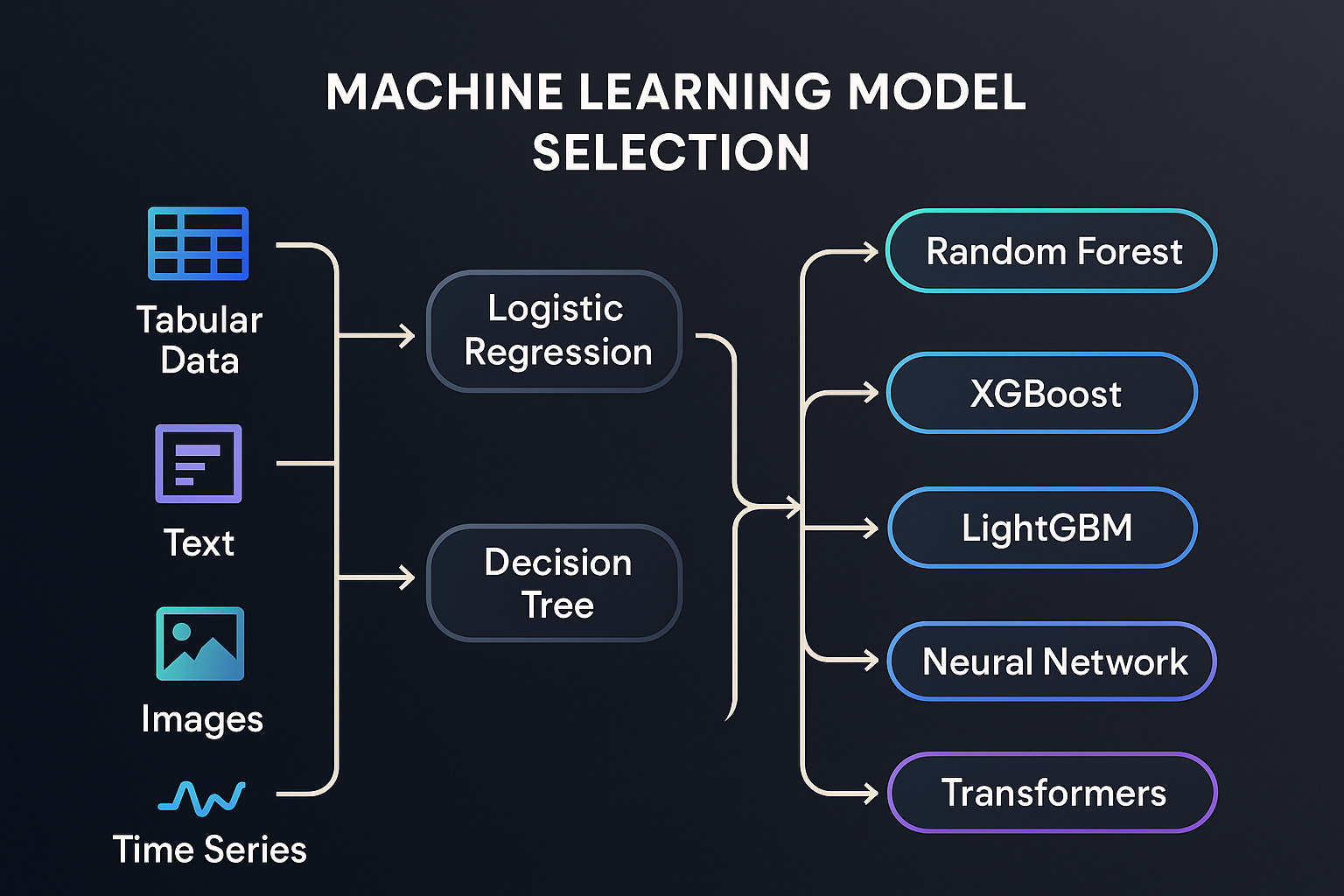
Key Algorithms In Machine Learning
Machine learning relies on various algorithms to analyze data and make predictions. Each algorithm has unique strengths and works best with certain types of data. Understanding key algorithms helps in choosing the right model for different tasks.
Decision Trees And Random Forests
Decision trees split data into branches to make decisions. They are easy to understand and visualize. Random forests combine many decision trees to improve accuracy. This method reduces errors and handles complex data well.
Support Vector Machines
Support vector machines (SVM) find the best boundary to separate data into classes. They work well with small to medium-sized datasets. SVMs handle both linear and non-linear data using special functions.
Neural Networks And Deep Learning
Neural networks mimic the human brain’s structure with layers of nodes. Deep learning uses many layers to learn complex patterns. These models excel in image and speech recognition tasks.
Clustering Techniques
Clustering groups similar data points without labels. It helps discover hidden patterns in data. Common methods include k-means and hierarchical clustering. These techniques are useful for market segmentation and data exploration.
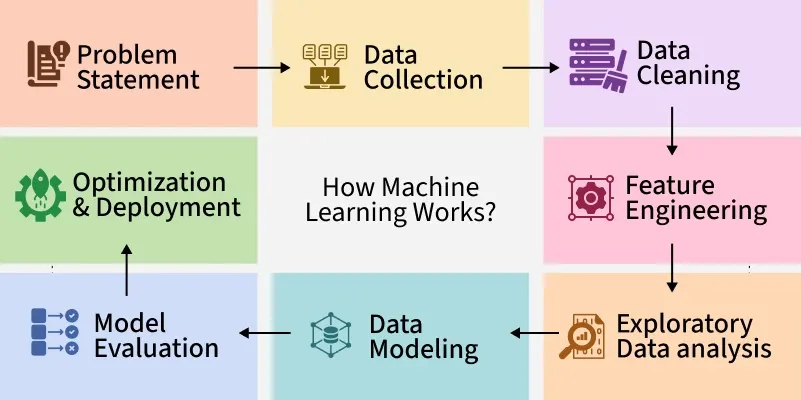
Data Preparation For Models
Data preparation is a key step in building machine learning models. It sets the foundation for accurate predictions. Raw data often contains errors and irrelevant information. Preparing data improves model quality and speed.
This process includes cleaning, transforming, and selecting features. Each step helps the model learn the right patterns. Proper handling of data balances the model’s view of the world.
Data Cleaning And Transformation
Data cleaning removes errors and missing values from datasets. It fixes typos, duplicates, and inconsistent formats. Clean data prevents wrong model decisions. Transformation changes data into a usable format. Scaling and normalization adjust data range. This makes different features comparable. Transformation also converts text into numbers. This is vital for many algorithms.
Feature Selection And Engineering
Feature selection finds the most important data points. It removes noise and reduces complexity. Fewer features speed up training and reduce errors. Feature engineering creates new data from existing features. It can reveal hidden relationships. Examples include ratios, sums, or differences. Good features help models understand data better.
Handling Imbalanced Data
Imbalanced data means some classes appear less than others. This can cause models to ignore rare cases. Balancing techniques fix this issue. Oversampling duplicates rare examples. Undersampling reduces common ones. Synthetic data generation creates new samples. Balanced data helps models learn all classes fairly.

Credit: skillfloor.com
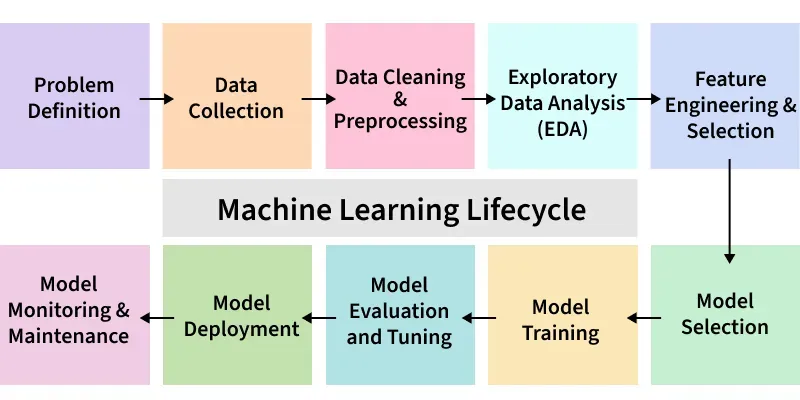
Model Training And Evaluation
Model training and evaluation are key steps in building machine learning data models. Training helps the model learn from data. Evaluation checks how well the model performs on new data. Both parts ensure the model is useful and reliable.
During training, the model finds patterns in the input data. Evaluation measures if these patterns help predict correct outcomes. Good training and evaluation improve accuracy and reduce errors.
Training Techniques
Training techniques guide how a model learns from data. One common method is supervised learning, where the model learns from labeled examples. Another is unsupervised learning, which finds patterns without labels. Reinforcement learning teaches models through rewards and penalties. Choosing the right technique depends on the problem and data type.
Cross-validation Methods
Cross-validation checks how well the model generalizes to unseen data. It splits data into parts for training and testing. K-fold cross-validation divides data into k groups. The model trains on k-1 groups and tests on the remaining one. This process repeats k times. It helps prevent overfitting and ensures stable results.
Performance Metrics
Performance metrics show how well a model works. Accuracy measures correct predictions out of total predictions. Precision checks correct positive predictions out of all positive guesses. Recall finds correct positives out of actual positive cases. The F1 score balances precision and recall. Choosing the right metric depends on the task and goals.
Speeding Up Insight Generation
Speeding up insight generation is key for businesses using machine learning. Fast insights help teams make smart choices quickly. It saves time and resources while improving results. Machine learning data models benefit greatly from faster processing and analysis. This section covers three ways to speed up insight generation effectively.
Automated Machine Learning Tools
Automated machine learning tools reduce manual work. They handle tasks like data cleaning, feature selection, and model training. This saves hours or even days of work. These tools allow users with less expertise to build models. Automation speeds up the entire data modeling process. It helps deliver insights faster without sacrificing quality.
Real-time Data Processing
Real-time data processing enables instant analysis of incoming data. It avoids delays caused by batch processing. This method is crucial for applications needing quick responses. Streaming data pipelines deliver fresh data continuously. Models update predictions as new information arrives. Real-time insights improve decision-making in fast-paced environments.
Scalable Infrastructure
Scalable infrastructure supports handling large data volumes efficiently. Cloud platforms allow easy expansion of computing power. It helps process more data without slowing down. Distributed systems divide workload across multiple machines. This reduces bottlenecks in data processing. Scalable setups maintain speed as data size grows.
Applications Unlocking Insights
Machine learning data models help find patterns in large data sets. These patterns lead to useful insights. Many industries use these models to improve decisions and results. The ability to analyze data quickly and accurately changes how businesses and services operate.
Predictive Analytics In Business
Businesses use predictive analytics to forecast trends and behavior. These models predict customer needs and buying habits. This helps companies create better marketing strategies. They also improve inventory management. Predictive analytics reduces risks and increases profits.
Healthcare And Medical Diagnosis
Machine learning aids doctors in diagnosing diseases. Models analyze patient data and medical images. They detect signs of illness earlier than traditional methods. This leads to faster treatment and better patient care. Machine learning supports personalized medicine plans.
Fraud Detection And Security
Financial institutions use machine learning to spot fraud. Models identify unusual transactions and behaviors. This helps stop fraud before it causes damage. Security systems also use these models to prevent cyber attacks. They protect sensitive data and keep systems safe.
Challenges And Future Trends
Machine learning data models are growing fast across many fields. Yet, they face several key challenges that slow progress. These obstacles shape how models develop in the near future. Understanding these issues helps us see where the technology is headed.
Interpretability Of Models
Many machine learning models act like black boxes. They give results but do not explain how. This lack of clarity makes users unsure about trusting the outcomes. Simple models like decision trees offer more clarity but less power. Complex models like deep learning excel in accuracy but lack transparency. Improving model interpretability is a major focus. Researchers work on tools that explain decisions clearly. This helps users trust and adopt AI solutions more.
Ethical Considerations
Ethics in machine learning is a growing concern. Models can inherit biases from their training data. These biases may lead to unfair or harmful results. Privacy is another critical issue. Models need large data, but users want their data protected. Balancing data use and privacy is challenging. Responsible AI development involves fairness, transparency, and accountability. Ethics will guide how models are built and used in the future.
Emerging Techniques And Innovations
New methods aim to solve old problems in machine learning. Techniques like explainable AI seek to make models easier to understand. Federated learning allows training without sharing raw data, enhancing privacy. AutoML automates model design, saving time and effort. Quantum machine learning explores new computational power to boost performance. These innovations promise to improve model accuracy, fairness, and usability. The future of machine learning looks bright with these advances.
Credit: ai.plainenglish.io
Frequently Asked Questions
What Are The Main Types Of Machine Learning Data Models?
Machine learning data models include supervised, unsupervised, and reinforcement learning. Each serves different purposes in pattern recognition and prediction tasks.
How Do Data Models Improve Machine Learning Accuracy?
Data models help identify patterns and relationships in data. Accurate models lead to better predictions and decision-making in machine learning applications.
Why Is Data Quality Important For Machine Learning Models?
High-quality data ensures models learn correctly. Poor data can cause errors, reducing the model’s reliability and performance significantly.
How Do You Select The Best Machine Learning Data Model?
Choosing the best model depends on the data type, problem complexity, and desired outcome. Testing multiple models helps find the optimal one.
Conclusion
Machine learning data models help computers learn from data. They find patterns and make predictions. Choosing the right model depends on your data and goals. Testing and improving models is important for better results. These models are used in many fields today.
Understanding them can help you solve problems faster. Keep learning and exploring different models. This knowledge will grow your skills over time.